PCSX2 Optimization
Many people have visited the forums giving ideas on how and where Pcsx2 should be optimized. While most ideas sound solid on the outside, they usually will not work in practice for various reasons. This blog will answer some of those burning questions on what Pcsx2 optimizations are important and where development work should be put in to make things run faster. We will touch on why the GPU is the bottleneck on some games and why the CPU is on others. We will also go into the distribution of workload of the various components of Pcsx2 as it is computing away. And most important, we will cover plugin design so that system resources are distributed nicely.
First a note to the people that have played around with optimization or will play around with it. Be careful when measuring performance with frames per second! If anyone told me their optimization gained 5 fps for a certain game, I would not understand what that means! Why? Well if a game went from 5 fps to 10 fps, that means each frame took 200ms and now it takes 100ms. The optimization saved 100ms of CPU time per frame and now the game is 2x faster (this doesn't happen anymore)! If a game went from 60 fps to 65 fps, each frame took 16.6 ms and now it takes 15.4 ms. This is only 1.2 ms of saved time per frame, and the game is only 1.06 times faster. Which optimization do you think is better? Also a 1-2% speed difference is not statistically big enough to say that the optimization is useful. In fact, the fps counter in the title bar fluctuates between 1-2% all the time. So you'll just be picking up noise.
Introduction
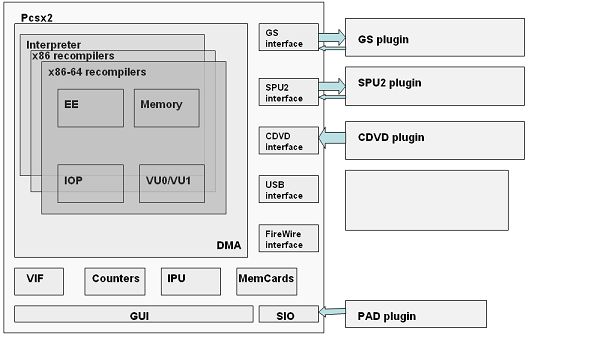
The major components of Pcsx2 are shown in the figure. The heart of Pcsx2 is the dynamic translators of the various PS2 instruction sets, most often called the recompilers. Note that there are three hearts that Pcsx2 can be compiled with depending on your CPU: the interpreter (actually always present), x86, and x86-64. Starting with 0.9.3, Pcsx2 has been retrofitted to compile the interpreter on any little-endian CPU architecture by compiling with the PCSX2_NORECBUILD define. There is also the memory management scheme that factors into dynamic translation since memory accesses can be optimized away instead of calling one huge MemoryRead(address, value) that redirects execution to the various hardware components. The DMA connects all data that is passed to the sub-components of Pcsx2. To the right are the components that are just interface stubs that interact with the plugins. At the bottom are the components that are implemented in Pcsx2 without any plugins. The reason for no plugins is that these components require tight synchronization between the Pcsx2 hardware registers, so having the component in a plugin will unnecessarily complicate and slow down things. Note that IPU can be argued to be a plugin on its own, however the actual MPEG2 decoding part of IPU is not the problem as much as the DMA communication between it and the EE.
The Graphysic Synthesizer (GS) plugin accepts a stream of commands to render geometry to its 4Mb video memory. This stream usually comes from VU1, VIF, or a DMA transfer. Data from VU1 is usually 3d geometry, data from VIF/DMA is usually textures or static 2D geometry. From time to time, the EE can request to read the GS memory from the VIF. Also, the GS sets various hardware registers so that the EE can synchronize with it. In MTGS mode, the GS has its own thread to do the stream processing and these hardware registers are emulated on the main EE thread to avoid having the EE wait for the GS to complete. In this way, the GS and EE can be detached and memory won't get corrupted. Ideally the GS plugin should offload as much computation off to the GPU and leave the CPU alone, this however is possible to a certain degree because of drivers (see the "Graphics Synthesizer, GPUs, and Dual Cores" blog).
The Sound Processing Unit (SPU2) plugin accepts a stream of commands through DMA. The stream usually writes/reads SPU2 memory and sets various channel modes. These channels play their data on a separate thread that produces raw PCM data to send to the sound card. At the moment, the communication between SPU2 and DMA is pretty buggy.
The CDVD plugin just worries about reading data from ISOs or DVD drives. Various caching and read-ahead techniques have to be applied in order to make the reading fast and not noticeable to the user.
The rest of the plugins are either not implemented like USB and FireWire or are pretty standard across emulators.
Optimization
When running, Pcsx2 spends most of its time in recompiled code (EE/IOP or VUs). When in the EE recompiler, most components are executed as hardware registers are written through the memory write functions. About every 512 EE cycles, the recompilers call cpuBranchTest to update counters, give IOP enough time to catch up, and perform other system stuff. The VU programs are usually executed as soon as the program is started in the VIF. If VU1 is executed, the recompilers don't exit until the VU program exits. If VU0 is executed, only 512 VU cycles are executed then control is given to the EE so it can catch up (synchronizing VU0 can be very tricky). IOP recompilers usually don't take up a lot of CPU time. Besides the fact that IOP runs 8 times slower than EE, it is also a 32bit processor, so things are fairly quick. The rest of Pcsx2 time is spent in pipelining the data through the various components. A good amount of time is also spend in the VIF UNPACK function, however this function is super-optimized (see iVif.cpp or iVif.S) so nothing can be done about that anymore. IPU also does MPEG2 decompression, so it is arguably computationally intensive during movies (however this isn't the case at all).
Because Pcsx2 is written in C/C++, function calls and pipelining is very fast. Many people believe that rearranging code and optimizing the calling conventions will speed things up. This is not the case at all. Although there do exist functions that could benefit from some hand-coded assembly, you will not see a statistical speed difference because the assembly code might not have improved speed too much, or the function is not called often enough to really matter. For example, it is stupid to optimize the recInit function, it is called only once per game!
Recompiler Optimizations
In short, don't waste your time optimizing the ADD or MULT instruction ...or any single instruction for that matter. The bottleneck of the recompilers is the way the registers are allocated. Also, registers are not tracked across simple blocks meaning that they are all dumped to memory at the end of each block, which is very suboptimal. My advice is not to touch any recompiler unless you know what is going on. If you are inclined to optimize recompilers, do the EE. The VU recompilers are very fast at the moment, so don't waste your time because you might kill compatibility... and IOP is just not worth it. When running a profiler, you might see the cpuBranchTest function pop up a lot... don't waste your time by rearranging code out of the function or trying to call the function less frequently, it won't work.
GS plugin optimizations
There have been various suggestions to use shaders to offload as much computation as possible. This is exactly what ZeroGS does! In fact, ZeroGS does it so well that your GPU will cry (hence the name KOSMOS). The biggest problem with the GS plugin is managing the render targets and caching the textures. Also, the trick to everything is never (and I really mean never) to transfer GPU memory to system memory. This problem is actually very common with many games because game developers just do crazy shit with the GS... sometimes I get the urge to email companies asking them 'what were you on when you programmed this?'. This is the reason why certain games are much slower than others. Sometimes the problem is fixable, sometimes it isn't (this is a good time to mention that the ocean zbuffer bug in FF12 is exactly due to this problem... and ZeroGS ingeniously ignores the memory transfer so FF12 is nice and fast... hence the bug).
Someone in the forums suggested executing VU1 instructions in the GPU vertex shaders. If you look at the shader and VU instruction sets, you'll see that they are very similar, so I can understand why someone would think this. However this is not possible because VUs are way more complex than vertex shaders! In fact, it is suicide to consider the amount of code reengineering that would have to be done just to get the GPU to execute a simple VU program... the GPU already has enough work to do. While on the subject of VU, it is also useful to mention that it is suicide to even consider putting the VU recompilers in their own CPU thread that can execute concurrently with the EE! Making things multi-threaded is tricky because of the data sharing between the two threads. In fact, putting the VU execution on another thread would probably slow things down more than speed up. The reason multithreading on the GS works so well is because the EE doesn't have to stop to synchronize with the GS, all it has to do is copy the stream it wants to send to the GS in a temporary buffer. The GS plugin will process it when it gets the time.
SPU2 optimizations
Don't know what's going on here. SPU2 really needs reworking. And it isn't just the plugin, there is a whole synchronization issue with DMA and SPU2 that has to be taken care of. The SPU2 should be multithreaded and it shouldn't require any huge synchronization with the main thread. If anyone will work on something, it should be SPU2.
Other optimizations
Most other components of Pcsx2 are already pretty optimized. To summarize, the biggest bottlenecks are the recompilers, GS plugin, and SPU2. Currently x86-64 versions of the recompilers are being developed. ZeroGS OpenGL will be released as open source soon, so people can contribute their own changes if necessary. Actually, future versions of ZeroGS will have a complex patch system that will enable gamers to tweak settings so that the game is as fast as possible (even dual core users can see a big performance gain with the correctly tweaked settings). No one is maintaining SPU2.... but that will change if this continues.
The last hope for optimization is actually x86-64. As to how much performance will increase... not even I know, but we shall see later in the year when Pcsx2 x64 releases (for Linux too).
Moral of the blog Optimization is time consuming and it is more of an art than science. Programs are developed much faster and have less bugs when you don't have to worry about optimizing (Java is a great example of a language where it is easy to develop programs, but very hard to have it run fast.. by design I guess). But no matter the application, having it go faster is much better than having it go slower. A lot of game companies spend a lot of money optimizing their code because it is that important. The reason most newer games have beautiful graphics running in real-time is not just because GPUs are getting faster, but also companies are getting better at optimizing their game engines. For example, games when the PS2 was first released look inferior to what new PS2 games look today. And with the way things are going in the software industry, it looks like C++ will stick around for a very long time because of its optimization capabilities. Learn C++, there are many books I can recommend, but the best way to learn is to actually go and program something.